3
我試圖完全理解Differential Synchronization algorithm,特別是保證交付方法(第4節)。瞭解Neil Fraser的差分同步算法
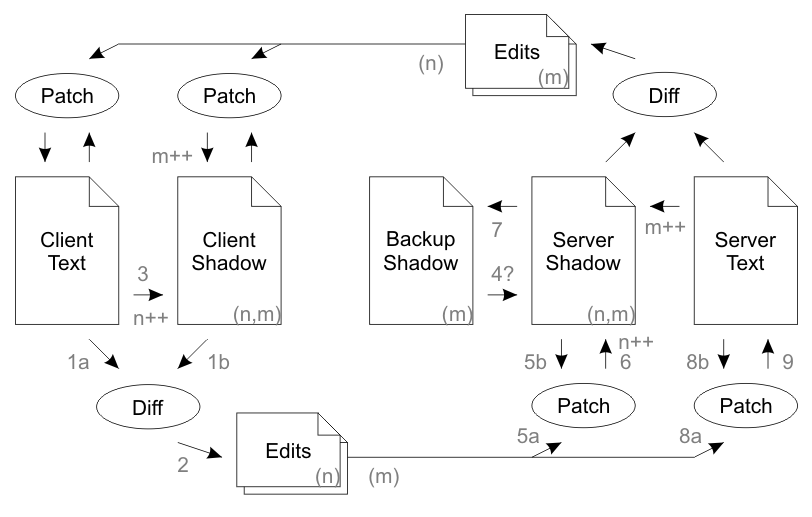
我不明白爲什麼有必要在同步週期的上半編輯堆棧。
的編輯的目的堆疊如下(從第二段在部分4中複製):
[...] in the case of packet loss, the edits are queued up in a stack and are retransmitted to the remote party on every sync until the remote party returns an acknowledgment of receipt.
有道理。但後來在第六段(在丟失返回的數據包情況下),它說:
This indicates that the previous response must have been lost. Therefore the server deletes its edit stack and copies the Backup Shadow into Shadow Text (step 4).
所以,就我的理解:
在正常的操作:編輯堆棧 (在上半部分)將包含單個條目,該條目在下一個同步週期期間被確認並移除。
如果發生網絡錯誤:客戶端無法確認編輯棧,然後服務器將簡單地清除它。
如果這是正確的,那麼在上半部分的編輯堆棧要麼是空或包含一個條目。此外,在任何情況下,單一條目都不會(重新)發送給客戶。使它完全無用?!
顯而易見的問題是爲什麼我們需要編輯棧(在上半部分)呢?
我確定我錯過了一些重要的東西。請幫助我。