3
所以,我試圖製作一個程序,將電腦變成代理using this。除了gzip/deflate頁面,它一切正常。C# - GZipStream幻數不正確?
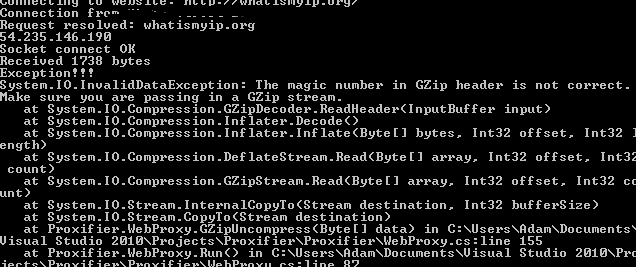
每當我嘗試解壓時,都會得到一個InvalidDataException,指出GzipHeader中的幻數不正確。
我用這個函數:
private byte[] GZipUncompress(byte[] data)
{
using (var input = new MemoryStream(data))
{
input.Seek(0, SeekOrigin.Begin);
using (var gzip = new GZipStream(input, CompressionMode.Decompress))
using (var output = new MemoryStream())
{
output.Seek(0, SeekOrigin.Begin);
gzip.CopyTo(output);
return output.ToArray();
}
}
}
解壓縮數據。錯誤:
error http://gyazo.com/c59de705a264cda47d670ae9b03dfa39.png
{kind=link}
任何幫助,將不勝感激。
編輯:我似乎已經得到了一個地方!
正如usr建議,我應該編寫一個HTTP解析器來獲取正文並解壓。
前解析:http://pastebin.com/Cb0E8WtT
解析後:
這是我使用去身體的方法:
private byte[] HTTParse(byte[] data)
{
string http = ascii.GetString(data);
char[] lineBreak = crlf.ToCharArray();
string[] parts = http.Split(lineBreak);
List<byte> res = new List<byte>();
for (int i = 1; i < parts.Length; i++)
{
if (i % 2 == 0)
{
Regex r = new Regex(@"(.)*: (.)*");
Regex htt = new Regex(@"HTT(.)*/(.)*.(.)* d{1,50} (.)*");
if (!r.IsMatch(parts[i]) && !htt.IsMatch(parts[i]))
{
//Console.WriteLine("[TEST] " + parts[i]);
res.AddRange(ascii.GetBytes(parts[i]));
res.AddRange(ascii.GetBytes("\r\n"));
}
}
}
return res.ToArray();
}
但是,我仍然得到一個錯誤說「魔GZip頭部中的數字不正確,請確保您傳入的是GZip流。「編輯(2):從here複製一個答案後,我設法成功解壓身體。
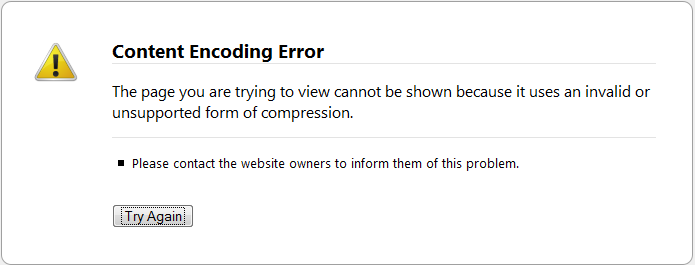
新問題:Firefox。
error http://gyazo.com/7c40af607471fbdd3c4968af547004b6.png
{kind=link}
現在我不確定是否我甚至需要解壓縮的gzip頁面..
我在哪裏錯了現在沒有了?
可能數據不會被解壓縮。看看字節。他們看起來怎麼樣。 – usr
作爲一個方面說明:你不需要「倒帶」一個新鮮的'MemoryStream':'Seek(0,SeekOrigin.Begin)'是多餘的 –
@usr:http:// pastebin。com/Cb0E8WtT這是whatismyip.org的請求,它看起來像我需要從頭中分離響應。任何想法我可以做到這一點? –