0
我在特徵識別中找到卷積的所有設計實例都通過使像素值爲1或-1來「簡化」卷積運算。它使一個非常簡單的操作(通過過濾器像素,和結果乘以輸入像素,然後通過像素數劃分):什麼卷積操作用於圖像識別?
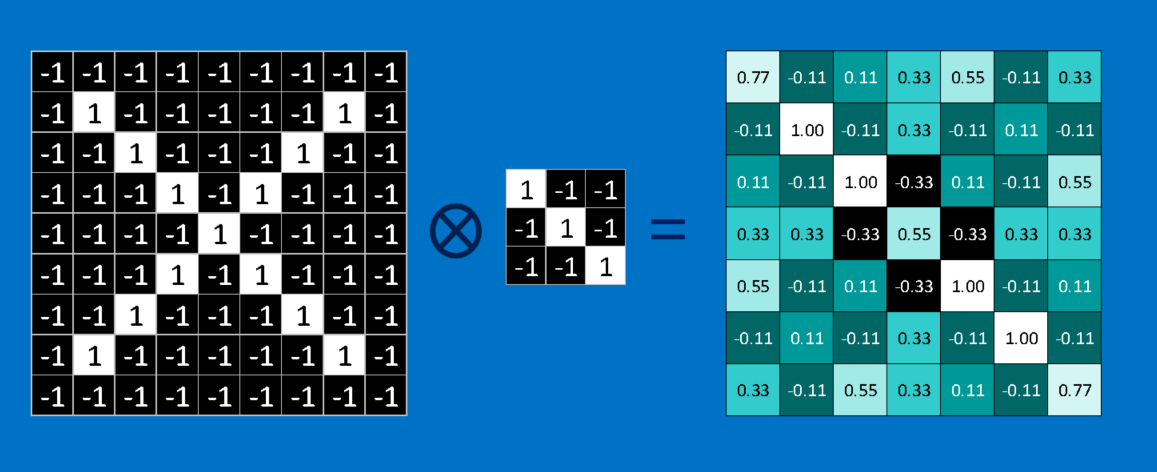
然而,它並不適合在那裏像素值將有範圍最圖片真的很有幫助。例如。 (0.0-1.0)或(0-255)。
對於這些輸入值,我找不到使用哪種算法的示例。我試着總結每個像素的差異,然後除以像素的數量得到一個整體的「錯誤」。然後激活等於最大錯誤。例如。 255 - 錯誤或1.0 - 錯誤。
它將永遠不會輸出負值,所以我沒有看到需要一個ReLU層。這讓我懷疑這是一種天真的做法,並不會真正起作用,但我不知道爲什麼。
那麼當輸入數據不是1/-1時使用的是什麼操作?
編輯這是我一直在尋找的例子:http://brohrer.github.io/how_convolutional_neural_networks_work.html
,它描述了卷積運算:
要計算特徵的匹配圖像的補丁,只是將特徵中的每個像素乘以圖像中相應像素的值。然後合併答案併除以該特徵中的像素總數。如果兩個像素都是白色(值爲1),那麼1 * 1 = 1。如果兩者都是黑色,則(-1)*(-1)= 1。無論哪種方式,每個匹配像素的結果爲1.同樣,不匹配是-1。
一個具體的例子,爲什麼我不認爲這適用於值爲[0.0,1.0]的像素。假設我們有一個值爲[0.5]的1x1過濾器。如果我們在輸入像素上運行它的值爲0.5,那麼我們得到0.25。同樣,如果我們使用[0,255]的顏色範圍,那麼我們很容易就會得到大於255的值。儘管我不確定這一點,因爲它不再是像素數據;它是在功能圖中激活的,對吧?
是啊,我知道如何卷積在輸入濾波器。我想我所說的是,如果每個輸入像素都有一個範圍的值而不是二進制1/-1,那麼它的工作原理還不清楚。我已經編輯了這個問題,以包含我基於此的示例。 –
除以1 /(所有這些數字的總和) – Tatarize
無論使用什麼權重,都需要進行標準化或預標準化。所以加起來用權重來衡量總和。這有點像權重總和中所有這些值的平均值。 – Tatarize