1
我有一些正則表達式來在標籤之間放置內容,如結果所示。如果我申請上導致文字相同的正則表達式表達我會得到標籤內的標籤......匹配特定不在標籤之間
原創內容:
Lorem存有悲123456坐在@twitter阿梅德, consectetur adipiscing ELIT例子。
結果:
Lorem存有[聯繫電話] 123456 [/電話]悲仰臥[總重量] @twitter [/ TW] 阿梅特,consectetur adipiscing ELIT並[a]例如,[/ A]。
RESULT第二時間:
Lorem存有[電話] [電話] 123456 [/電話] [/電話]悲坐 [總重量] [總重量] @twitter [/ TW] [/ tw] amet,consectetur adipiscing elit [a] [a] example [/ a] [/ a]。
什麼把我的正則表達式,以便不匹配,如果內容介於任何[]和[/]之間?
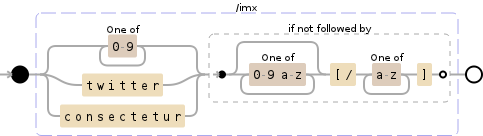
嘗試增加'(?!\ [\/[^] *])'到你的正則表達式模式的結束。 –
下面的答案是解決方法,而不是解決方案。 –