9
緩存是否有統一的理論? 也就是說,構造緩存和/或爲其優化的定理和算法集合?緩存理論
這個問題是故意寬泛的,因爲我期待的結果也很廣泛。 最大可實現加速的公式,緩存算法的度量標準,等等。 大學水平的教科書可能是理想的。
緩存是否有統一的理論? 也就是說,構造緩存和/或爲其優化的定理和算法集合?緩存理論
這個問題是故意寬泛的,因爲我期待的結果也很廣泛。 最大可實現加速的公式,緩存算法的度量標準,等等。 大學水平的教科書可能是理想的。
如果可以假設緩存命中比高速緩存未命中快得多,你會發現,加班時間,即使你只有高速緩存未命中,使用高速緩存仍然會以最快的速度還是比不使用緩存更快。
請參閱以下數學:
Number of hits = NumRequests - #CacheMisses
AverageTime = ((NumRequests-#CacheMisses) * TimePerHit + #CacheMisses * TimePerMiss)/NumRequests
如果我們再假設NumRequests是無窮大(這是一個限制問題,不懼怕微積分),我們可以看到這一點:
AverageTime = Infinity*TimePerHit/Infinity - #CacheMisses*TimePerHit/Infinity + #CacheMisses*TimePerMiss/Infinity
既與#CacheMisses項變爲零,但整個方程解析爲:
AverageTime = TimePerHit
授予此適用於請求數量無窮大時,但您可以看到這將如何通過使用緩存輕鬆加速您的系統。
絕大多數現實世界的緩存涉及剝削「80-20法則」或Pareto distribution。請參見下面的它的外觀
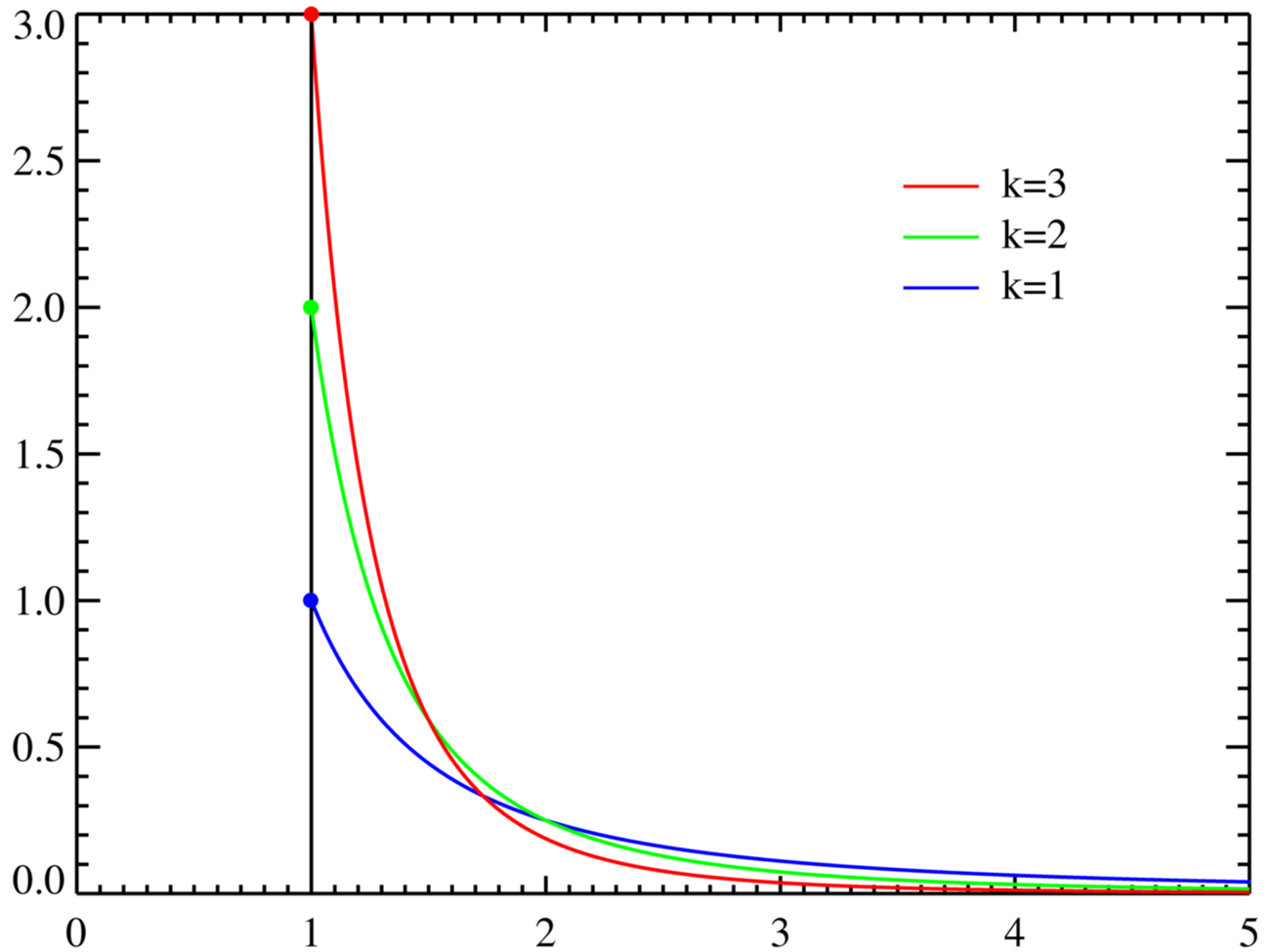
這表現在應用程序爲:
因此,我會說「緩存理論」是用盡一些額外的資源,這些資源通常是「稀有」但「快」以補償最活躍的重複的事情將會做。
你這樣做的原因是試圖「拉平」你做基於上述極不平衡圖表上的「慢」的操作次數。
我跟我的學校的一位教授聊過,他指着我朝着online algorithms, 這似乎是我正在尋找的主題。
緩存算法和頁面替換算法之間存在大量重疊。我可能會編輯這些主題的WikiPedia頁面以澄清連接,一旦我對這個主題有了更多的瞭解。
您的計算看起來非常好。不幸的是,這意味着緩存未命中的數量是不變的,這似乎不太可能。 正確的數字是: HitProbability * TimePerHit +(1 - HitProbability)* TimePerMiss – 2009-06-17 12:04:30